My Git Story
A little background
Our source control story started many years ago using a tool popular at the time in the .NET circles called Source Gear vault. This tool worked well in the beginning due to its simplicity, resemblance to the file system and a reasonably user-friendly UI. However, we hit a few issues with using this tool and with how it influenced our source control management strategy:
- Branching is not a central concept in this tool and was not easy to use
- The software is proprietary and is not very popular thus lacking support from large CI systems and other productivity tools
- Lack of community to find issues/best practices
- The application was not implemented correctly from the beginning making it difficult to change
- High licensing costs
- No rigid process of managing commits
We looked for alternative options there were not many. Git seemed like the best version control system available. It seemed to address all the issues mentioned above and presented a multitude of options for implementation of a successful source control management strategy.
Now we had to choose a platform to implement Git. Due to the high sensitivity of the software development area that we work in, we could not use a third party hosted solution, thus, unfortunately, eliminating Bitbucket or Github. We had to find an on-premise solution instead. As we are a .NET development house, we have decided to trial Team Foundation Server (TFS) with Git. TFS is a compelling software suite that is installable on-premise, and that has all the bells and whistles required for source control management in addition to Continuous Integration, Project management tools and other productivity services. Unfortunately, we found the licensing model to be very complicated and expensive and the User Interface to not be intuitive. Also, it did not demonstrate high performance, but that might have been due to our internal misconfiguration. So we looked further and discovered Gitlab.
Gitlab is an open source web-based Git, repository manager. Gitlabs UI resembles the user interface of Github and offers pretty much all the functionality provided by Github. The Community edition of Gitlab is distributed under the MIT license and can be easily installed on a Linux box. The tool also comes with inbuilt Continuous Integration and Issue tracking. The company behind it has a team of around 150 devs (as of December 2016) and over 1400 contributors (https://en.wikipedia.org/wiki/GitLab). It integrated well with lots of third-party services and had excellent documentation. After presenting this solution to the team, we have reached an agreement to go ahead and implement Gitlab as our version control system.
Now that we had a tool, I wanted to make sure that we pick a valid and consistent strategy for our software version control. We have started by looking at Gitflow.
About Gitflow
Gitflow is a source control workflow pioneered by Vincent Driessen at nvie. It acts as an extension to the “Feature Branch” workflow by providing an opinionated branching model centred around releases. There are numerous articles available online providing more details on this workflow; the critical part is that it focuses on having a master and development branches. All the work is done in feature branches. When the work is completed feature branches get merged back into develop branch and once a feature or a set of features are ready for release a release branch is created of the develop branch. The release branch can only then have commits to fix some bugs before release as well as changes to documentation and other pre-release tasks. Once the release is ready, it gets merged into the master and back into the develop branch as essential changes might have been done to the release branch. Once the version is released, the master branch gets tagged with the release version number, and the release branch gets deleted. Finally, if a fix to the application is required it can be done using Hotfix branches, these branches are created of the master branch and then get merged into both master and develop branches once completed source.
We have tried to use the classic Gitflow model, but unfortunately, we have hit a few issues:
- High focus on continuous delivery: Our processes did not allow us to continuously deliver changes to our products and required us to maintain multiple version of the same product. This was making it hard to use the classic Gitflow workflow with ephemeral release branches. We were struggling to keep the master always in a releasable state thus potentially introducing bugs in production.
- Maintaining ‘develop’ and ‘master’ branch: Let’s agree that merging and resolving conflicts is a laborious and time-consuming task. Doing this on two branches made it even harder. As we have a small development team having this burden on myself to maintain two branches did not work well, merge request processing was slow and we did not have confidence in the master branch.
- Complexity: The work-flow introduces complexity that probably is fine in bigger development teams but causes severe friction and efficiency impact in smaller ones.
After hitting these hurdles, I have decided to take a step back and look at alternative flavours of Gitflow. I still believe that the methodology is excellent it just needed a few tweaks to match closer to our development work-flow. First I looked at Github Flow.
Github Flow
Github Flow is a simplified version of GitFlow where you only have one master branch, and you manage all the development in feature branches which then get integrated into the master using pull/merge requests. This methodology is simple and robust and has been adopted by numerous companies successfully, but it still relies on the master branch to always be deployable and does not offer tools for managing multiple versions of the application. Finally, I stumbled upon Gitlab Flow.
Gitlab Flow
Gilab Flow offers two paths. First, one using a “production” branch, so all the development happens in feature branches that are merged into the master and when they are ready for release they get merged into the “production” branch. This way you have the benefits of having a branch that is stable and can be released at any point and the convenience of using “master” for all the current work. There are variations of this approach where you can add more environment-related branches like a “pre-production” branch. When a feature is ready to be deployed, it can be merged from master into the pre-production branch and then once the code is ready to go live the pre-production branch gets merged into the “production” branch. Hotfixes would be developed on feature branches and then merged into the master and pre-production. Essentially you create a one-way data flow for all the software changes.
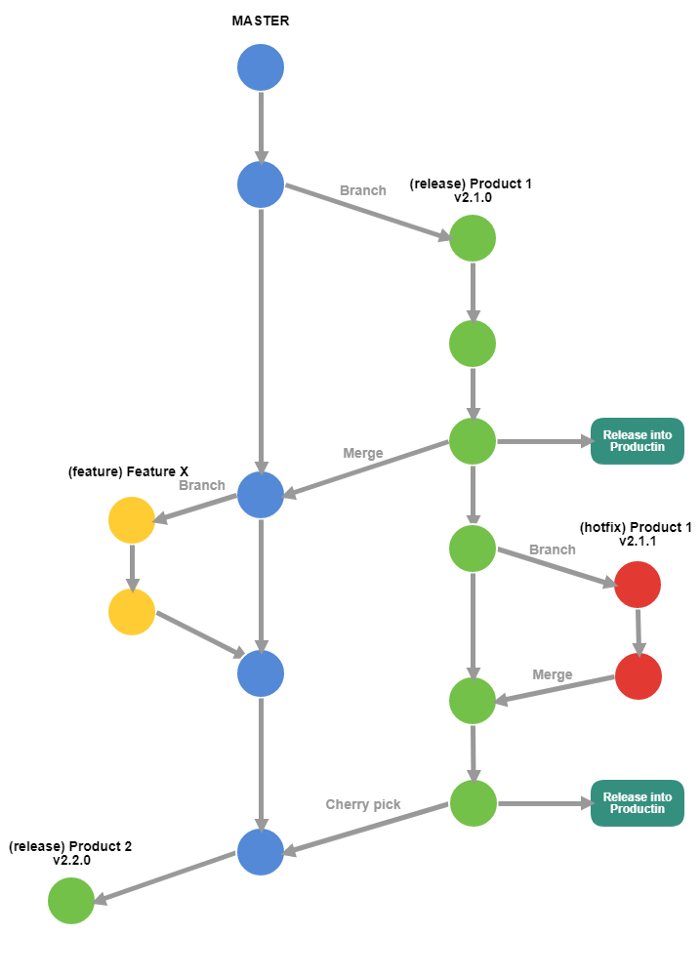
The last approach offered by Gitlab flow is using “release” branches. Each release branch should have a minor version number and would use master as the starting point. These release branches are created as late as possible in the development cycle to reduce the amount of time that has to be spent in propagating the changes to multiple release branches. After this release branch is announced, only critical bug fixes are done on this branch. Bug fixes are done in feature branches, then merged into master and then cherry-picked into the release branch. This is done to ensure that changes do not get forgotten to be merged into master. The title of this approach is ‘upstream first’. According to Gitlab documentation both Google and Red Hat practice this approach more info.This was the actual solution that matched the closest to what we were looking for. Now we had a master branch that we could work on via feature branches, multiple stable releases that we could patch and release into production whenever necessary. An approach to making isolated changes with a clear path and minimal room for error. I have outlined the process in the diagram below, and it has been working very well for us so far.
A few tips I found useful.
Squashing Commits
When working on feature branches, I tend to check-in my code multiple times to have a remote backup of the progress. Unfortunately, this created a somewhat messy git commit history. Squashing the commits allows merging all of the commits into a single one. Gitlab allows specifying whether the commits should be squashed in the specification of the merge request
https://docs.gitlab.com/ee/user/project/merge_requests/squash_and_merge.html.
Naming your branches
Picking a correct naming convention for branches was quite confusing to me and took me some attempts before I have figured out a clear and concise way of naming the branches. Here is the template that I have chosen:
[Type of Branch]-[Product]-[Description]
Type of Branch — this describes whether the branch is a ‘Feature’ a ‘Release’ or a ‘Patch’ (aka Hotfix) Product — as we build multiple products from the mono repository this contains the name of the product or ‘Generic’ for generic Features Description — describes the purpose of the branch, it could contain the feature id, or a general description if we are using this branch for working on multiple issues
Conclusion
We hope to move to one production branch in the future once our CI processes evolve but for now, Gitlab flow with release branches offers us the best flexibility and reliability compared to other ways of managing our code. I recommend to everyone to check out Gitlab and Gitlab flow and would like to thank the Gitlab ream for providing such a great peace of software.